第三章机器学习在交易中的简单应用
1机器学习的基本概念
1有监督学习和无监督学习
有监督学习就是有事先标注好的数据,如果数据标注是离散的,并且是代表一个类别的标签,并且训练样本使样本获得正确的类别标签,这样就是一个分类任务。如果是一个目标值,训练模型使其可以预测出新样本对应的数值——这时模型的目标是连续的,那这就是一个回归任务无监督学习就是没有人工主观标注的数据,只有目标和目标的客观特征值,但是还是可以通过对特征值的相关性的计算进行一个归类,这就是无监督学习中的聚类任务
2分类和回归
分类是实现有标注好的分类标签,训练分类模型,然后将新的样本归于已有的分类的过程回归是给定样本的目标值,训练回归模型,对一个新的样本,进行目标值的预测的过程在交易中,如果是预测未来股票是涨或者跌,这时就是一个分类的过程,是分类任务;如果是预测股票未来的股票是涨多少,还是跌多少,这时就是一个回归的过程
3模型性能的评估
如果使用算法来进行交易的话,最关心的就是模型是否可以准确地预测出股票的涨跌或者涨幅。实际上,模型是不可能做到百分之百准确的,这就需要我们对模型的性能进行评估,以便找到最可用的模型。要达到这个目的,我们就需要将掌握的数据集拆分为训练集和验证集,使用训练集训练模型,并使用验证集来评估模型是否可用举一个例子,假如有某只股票100天的价格数据,就可以将前80天的数据作为训练集,将后20天的数据作为验证集,同时评估模型分别在训练集与验证集中的准确率。如果模型在训练集中的得分很高,而在验证集中的得分很低,就说明模型出现了过拟合的问题;而如果模型在训练集和验证集中的得分都很低,就说明模型出现了欠拟合的问题要解决这些问题,小瓦就需要调整模型的参数、补充数据,或者进行更细致的特征工程
2机器学习工具的基本使用方法
学习使用python的sklearn库进行常见的机器学习算法的学习
1KNN算法的基本原理
2KNN算法用于分类
1载入数据集并查看
scikit-learn内置了一些供大家学习的玩具数据集,其中有些是分类任务的数据,有些是回归任务的数据。首先我们使用一个最简单的鸢尾花数据集来演示KNN算法在分类中的应用输入代码如下:
#codeing=utf-8
import matplotlib.pyplot as plt
import seaborn as sns
#导入鸢尾花数据和KNN模型
from sklearn.datasets import load_iris
from sklearn.neighbors import KNeighborsClassifier
if __name__ == "__main__":
iris = load_iris()
print("keys:", iris.keys())
print("feature_names:", iris.feature_names)
print("target:", iris.target)
sepallengthsepalwidthpetallengthpetalwidth
数据集中的样本分为3类,分别用0、2这3个数字来表示
这个数据集的目的是:根据样本鸢尾花萼片和花瓣的长度及宽度,结合分类标签来训练模型,以便让模型可以预测出某一种鸢尾花属于哪个分类
2拆分数据集
将数据拆分为训练集和测试集输入代码如下:
#codeing=utf-8
import matplotlib.pyplot as plt
import seaborn as sns
#导入鸢尾花数据和KNN模型
from sklearn.datasets import load_iris
from sklearn.neighbors import KNeighborsClassifier
#导入数据集拆分工具
from sklearn.model_selection import train_test_split
if __name__ == "__main__":
iris = load_iris()
#print("keys:", iris.keys())
#print("feature_names:", iris.feature_names)
#print("target:", iris.target)
X, y = iris.data, iris.target
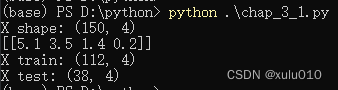
print("X shape:", X.shape)
print(X[:1])
#将X和y拆分为训练集和验证集
X_train, X_test, y_train, y_test = train_test_split(X, y)
#查看拆分情况
print("X train:", X_train.shape)
print("X test:", X_test.shape)
输出数据如下:可以看出,我们将数据集的特征赋值给了X,而将分类标签赋值给了y。通过查看X的形态和第一条数据,可知样本数量共有150个,每个样本有4个特征通过拆分,训练集中的样本数量为112个,其余的38个样本则进入了验证集
3训练模型并评估准确率
输入代码如下:
#创建KNN分类器,参数保持默认设置
knn_clf = KNeighborsClassifier()
#使用训练集拟合模型
knn_clf.fit(X_train, y_train)
#查看模型在训练集和验证集中的准确率
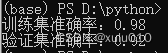
print("训练集准确率:%.2f" % knn_clf.score(X_train, y_train))
print("验证集准确率:%.2f" % knn_clf.score(X_test, y_test))
输出数据如下:注意这个数据并不是一个稳定值,因为每次切分的训练集和测试集都不一样,所以准确率也不一样,但是基本都是90%以上
需要说明的是,在scikit-learn中,KNN可以通过调节n_neighbors参数来改进模型的性能。在不手动指定的情况下,KNN默认的近邻参数n_neighbors为那么这个参数是最优的吗?我们可以使用网格搜索法来寻找到模型的最优参数
输入代码如下:
#codeing=utf-8
import matplotlib.pyplot as plt
import seaborn as sns
#导入鸢尾花数据和KNN模型
from sklearn.datasets import load_iris
from sklearn.neighbors import KNeighborsClassifier
#导入数据集拆分工具
from sklearn.model_selection import train_test_split
# 导入网络搜索
from sklearn.model_selection import GridSearchCV
if __name__ == "__main__":
iris = load_iris()
#print("keys:", iris.keys())
#print("feature_names:", iris.feature_names)
#print("target:", iris.target)
X, y = iris.data, iris.target
#print("X shape:", X.shape)
#print(X[:1])
#将X和y拆分为训练集和验证集
#X_train, X_test, y_train, y_test = train_test_split(X, y)
#查看拆分情况
#print("X train:", X_train.shape)
#print("X test:", X_test.shape)
#创建KNN分类器,参数保持默认设置
#knn_clf = KNeighborsClassifier()
#使用训练集拟合模型
#knn_clf.fit(X_train, y_train)
#查看模型在训练集和验证集中的准确率
#print("训练集准确率:%.2f" % knn_clf.score(X_train, y_train))
#print("验证集准确率:%.2f" % knn_clf.score(X_test, y_test))
# 定义一个从1-10的n_neighbors
n_neighbors = tuple(range(1, 11)) # [1-11)每个一个数取值,存储元祖,(1,2,3,...10)
# 创建网络搜索实例,estimator用KNN分类器
# 把刚刚定义的n_neighbors传入给param_grid参数
# cv参数指交叉验证次数为5
cv = GridSearchCV(estimator=KNeighborsClassifier(),
param_grid={"n_neighbors": n_neighbors}, cv=5)
# 使用网络搜索拟合数据集
cv.fit(X, y)
# 查看最优参数
print("最优参数:", cv.best_params_) # {"n_neighbors": 6}
文章为作者独立观点,不代表股票配资公司观点
相关文章

股民评论